{kind=link}
In simple terms Z-scores tell you how far away from the mean a value is, more specifically how many standard deviations away it is.
Often Z-scores can be used as an easy method of outlier detection, i.e. spotting the unusual.
Cycle Hire
In todays simple example we are looking at London Cycle hire data from the open public data sets on BigQuery bigquery-public-data:london_bicycles.cycle_hire.
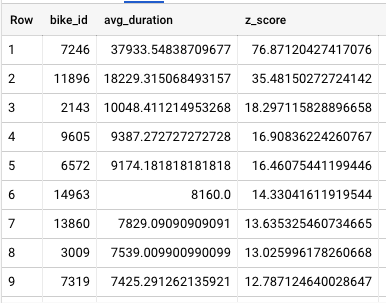
We will be using Z-scores to identify bikes that have much higher average duration than normal. We are specifically looking for bikes which are at least 3 standard deviations away from the mean.
Why?
This is of course an example use case, however if you were a Cycle hire operator you might want to have a method to identify which bikes should have more regular service intervals based on the average duration they travel for each trip.
Breakdown
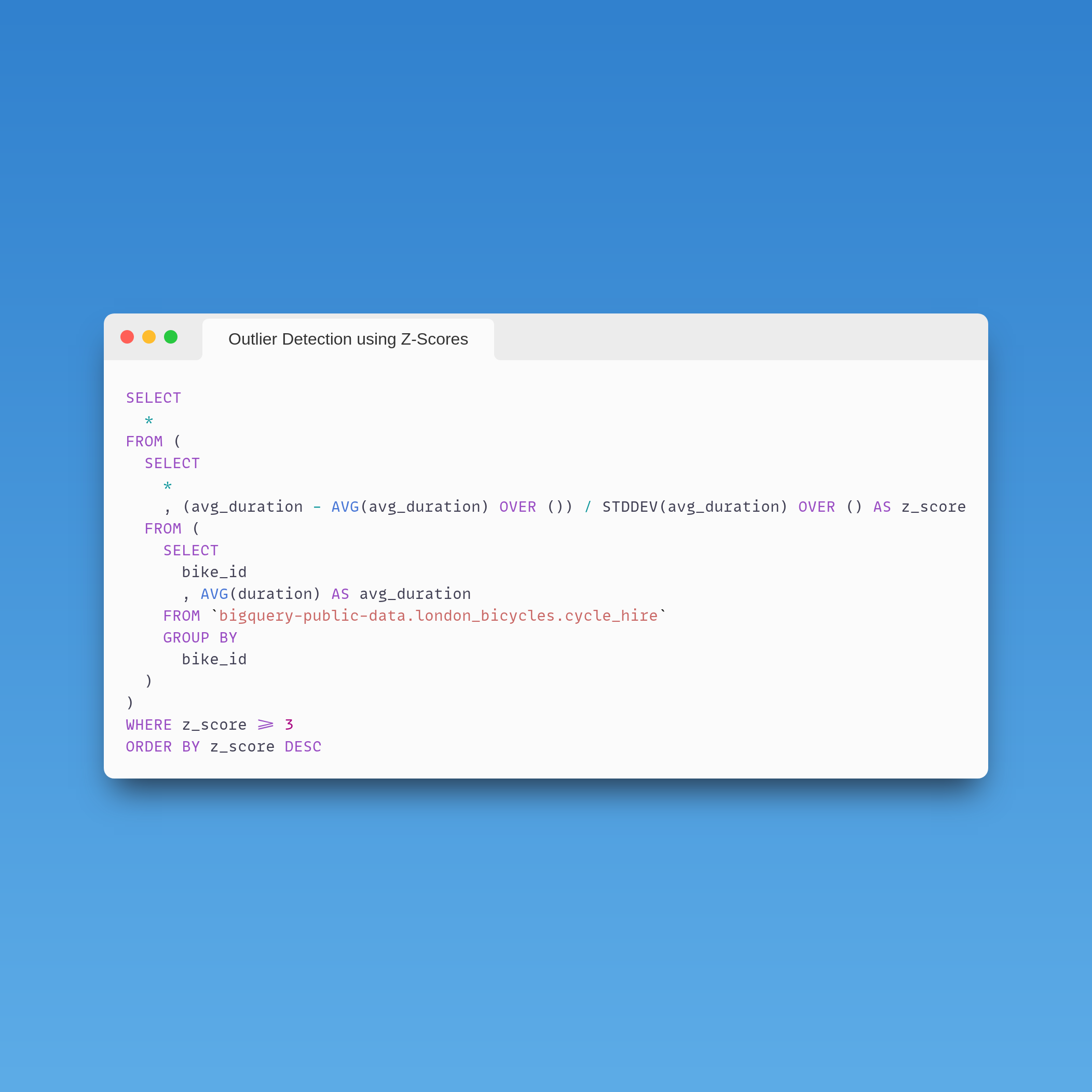
We are first taking the AVG(duration) of each bike_id
SELECT
bike_id
, AVG(duration) AS avg_duration
FROM `bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY
bike_id
We then calculate the Z-score for each bike_id, this is easy using WINDOW functions. The OVER() clauses after AVG and STDDEV allow us to calculate the respective values across the entire dataset against each row of data.
(avg_duration - AVG(avg_duration) OVER ()) / STDDEV(avg_duration) OVER ()
Finally we filter based on the z_score
WHERE z_score >= 3
When we run the query there are a total of 71 bikes out of 13k that match our criteria.