Your First Query

Blakey
—
Getting started with QueryStash, doesn't need to fill daunting. The only question you have to answer is what gets stashed first. Some might want to start with useful snippets, things you might use on a regular basis, others could jump right in through the project route and start organizing their own analytics work.
The important thing to remember for now is, this is just the start of your very own stash that will grow and develop with you.
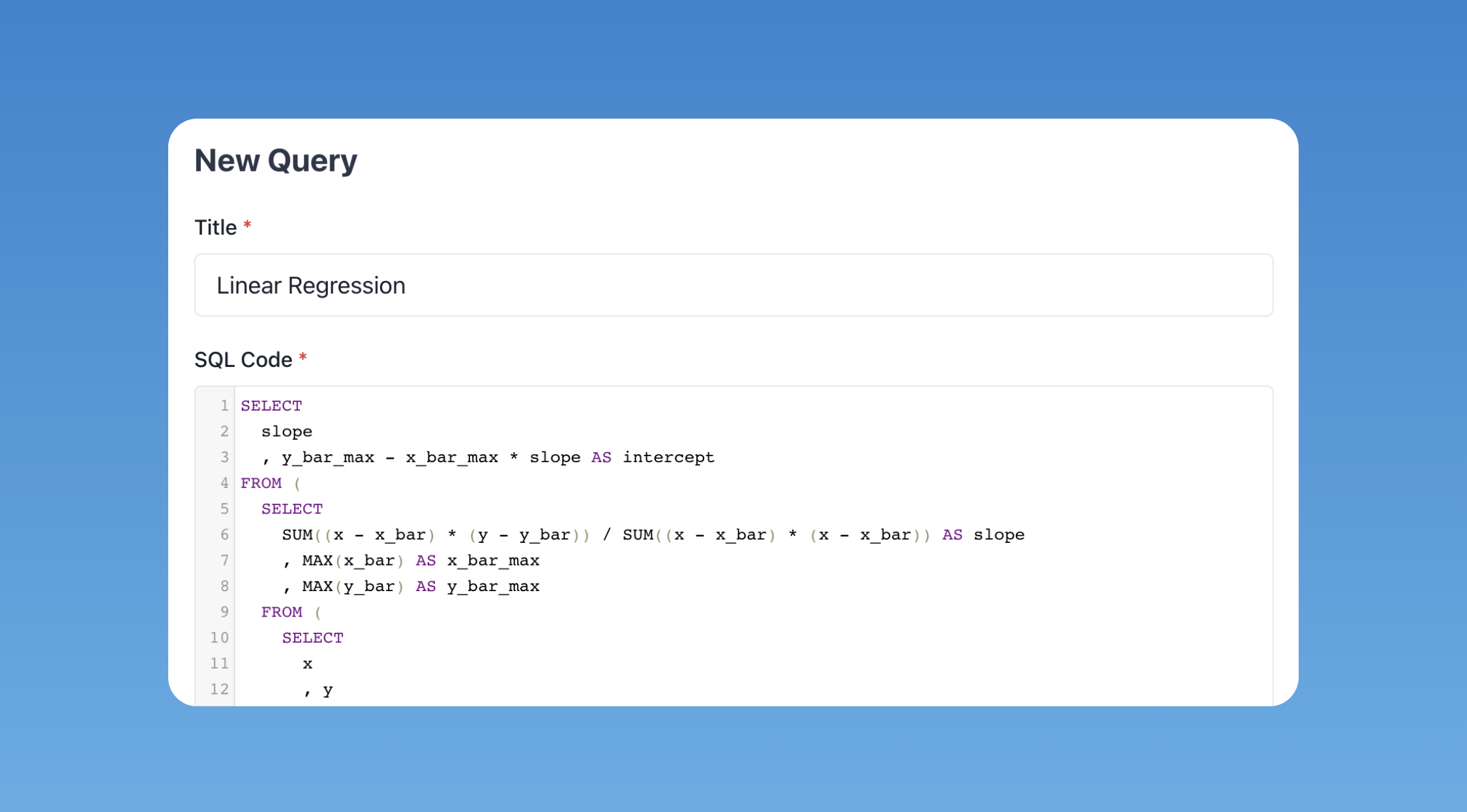
Once logged into the app the "New Query" button gets you straight into our query editor page.
Query Metadata
First things first, lets talk about metadata. We want to make sure you can find what you need as quickly as possible, keeping the flow of work is essential. To enable this we use a number of approaches to enrich metadata about your query that might be useful to trace it down.
To start with we have input from the query creator, yes yourself. We keep it fairly simple, broken into three key parts:
Title
Give it a sensible name, you stash will likely get very large over time. Let's make sure we use some common sense and a good consistent naming convention from the out start.
Tags
Grouping things together can help provide some organizational benefits, tags are a helpful way of creating what I like to think as loose groups. Things that overlap on certain topical areas. Lets say we were creating a number of queries related to how our team calculates a range of KPI's, it would be useful to add the tag 'kpi' to each query.
Tags could be anything you like, but again try to keep some consistency in your approach.
Some examples might include:
- functions
- stats
- examples
- windows
- snippets
Description
Tell your story, what is this query about. Keeps things specific and useful. Will this help you understand what the query is for in two years time, how would someone else understand it if they saw it.
Descriptions support Markdown to help you better structure your content. New to the Markdown concept check this great guide here for some tips and syntax.
SQL Query

Next up the main reason we are all here, the SQL code.
The SQL editor is designed to be as simple and easy to use as possible. It has all the common functionality built in that you would hope for. Syntax highlights, auto tabs, history of edits, etc... In fact if you are happen to be a BigQuery user, the editor is the exact same library behind the scenes.
Visibility
The last decision to make, who can see this query?
Public or Private the choice is yours, for most project related work its likely you want some privacy. However for more general useful snippets we encourage everyone to share their knowledge and techniques.
In future we will also be support sharing and teams to enable both targeted sharing and group wide collaboration.
Remember if you are on the FREE Starter plan you are currently limited to Public queries only. For more information on benefits of our paid Individual plan visit our Pricing Page
Save
Thats it your all set. Hit the Save button and start the stash journey.
Explore some example SQL queries...
QUALIFY by ROW_NUMBER for cleaner queries
Using QUALIFY you can greatly simplify your query when dealing with RANK and ROW_NUMBER, and avoid having multiple sub queries.

Spike Detection for Website Visits
To demonstrate one approach to spike detection, we are exploring website visitor data from the BigQuery Public Google Analytics sample data.

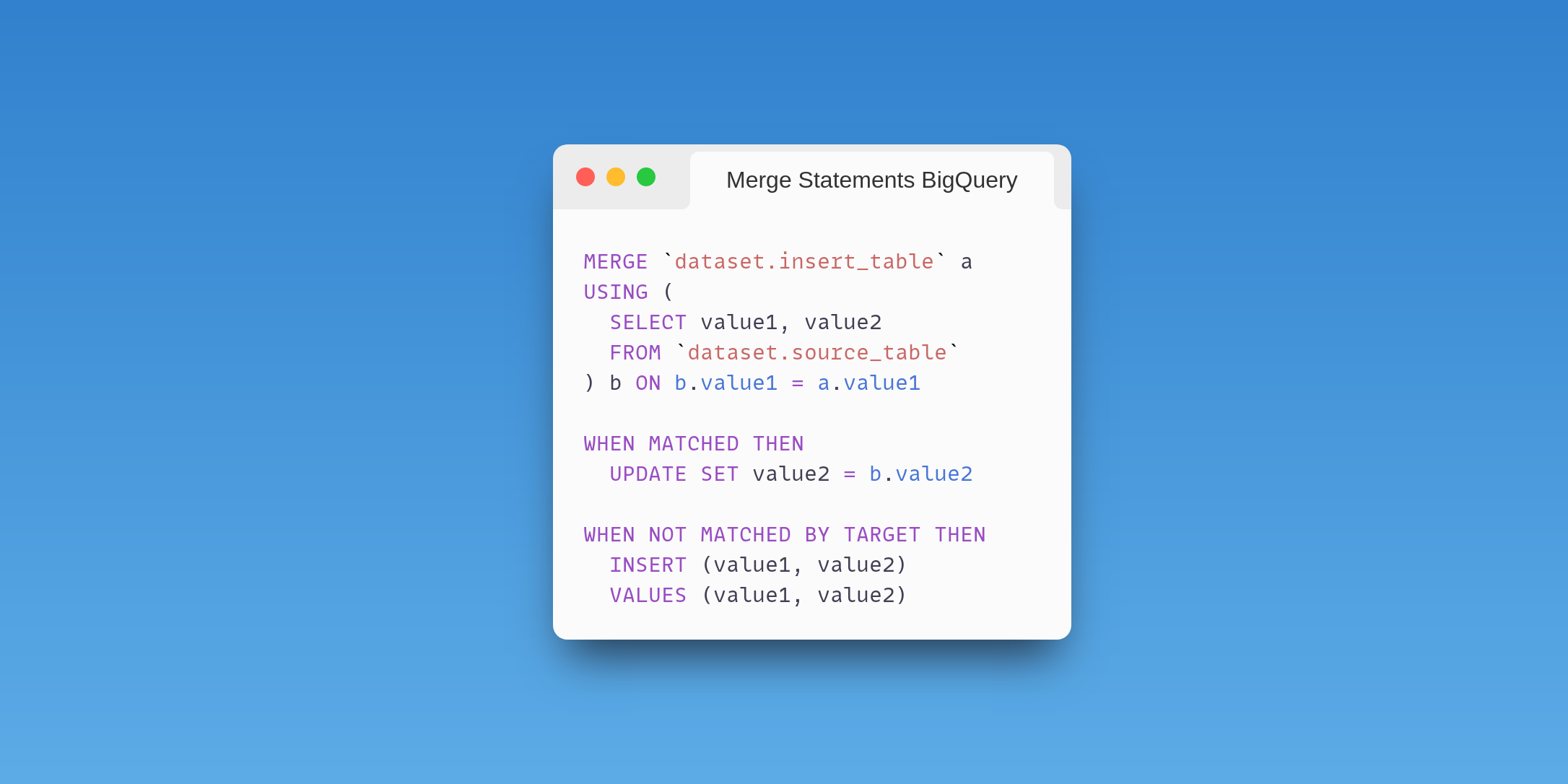
Merge Statements BigQuery
The combination of insert and update in a merge statement simplifies data processing where we don't know if a record already exists.
Create a Persistent Function on BigQuery
Persistent user-defined functions allow users to create custom functions that can be used across multiple queries and shared amongst users.

BigQuery Create ML Regression Model
Creating ML models has become even easier with BigQuery ML, create a new model in a few lines of SQL.

BigQuery Create Array of Structs
Working with flattened data might not always be the optimal way to work with data in BigQuery, use arrays to group data together into a single field.
