Search Your Stash

Blakey
—
The main purpose behind QueryStash is to help you organize you SQL code. Anything from a simple snippet, full analytics query or some useful examples. If you have already been through the process of creating your first query, you will have learnt that we capture extra metadata to help you later retrieve your queries in a simple manner.
This week we are pleased to introduce the first version of "Search".

General Search
Searching is as easy as Googling, oh wait they are the same thing right? Yes, just start typing and watch your stash update below.
By default the search is looking for potential query matches across all of the metadata we have for each query. Titles, tags, descriptions and the actual SQL code itself.
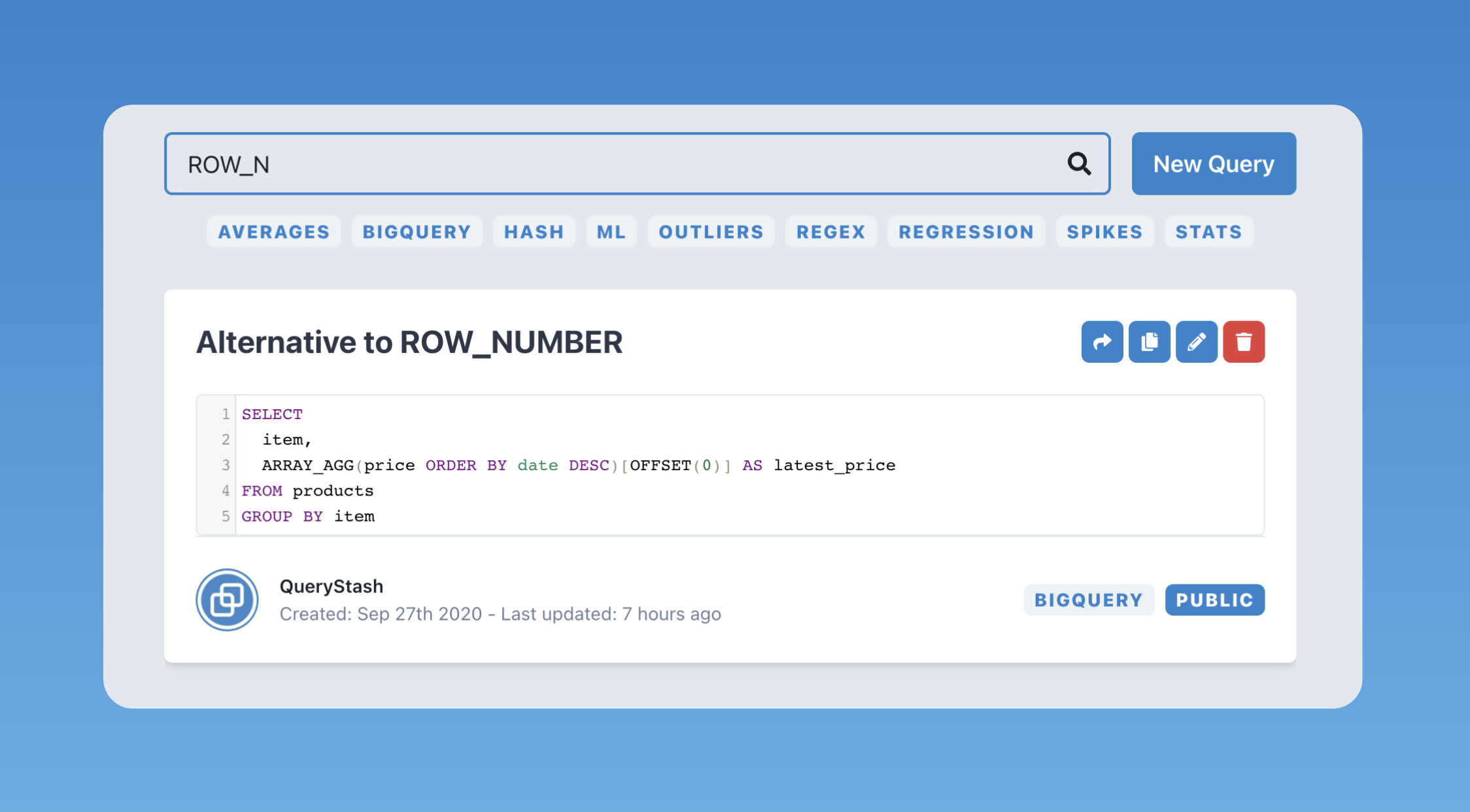
So if you know what function you are looking for just type it, for example:
Targeted Search
We said by default, what is not default?
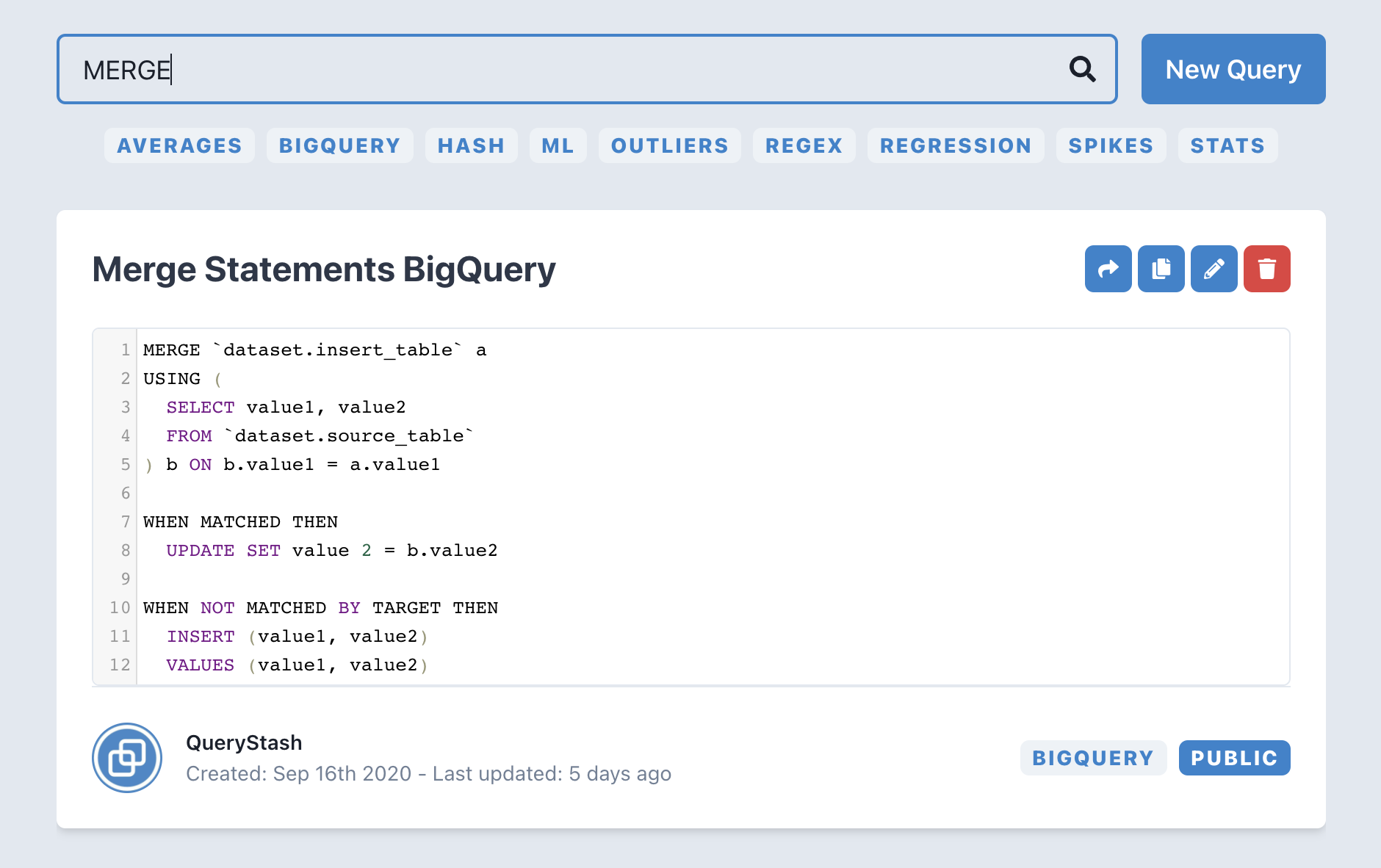
Well you can be a little more specific for cases where you want a more targeted search. We have some special key words that trigger target searches. tags, title and sql. You can use any of these words with a colon then your search term, to specifically search just the tags or just titles or just your SQL code.
Some examples:
- tags:bigquery - Returns all queries tagged with bigquery
- sql:table_name - Returns everything that uses a specific dataset table_name
- title:example - Returns all that have example in the title
In most cases the default search will work perfectly fine, however as your stash grows and becomes bigger and bigger, you might want to narrow things down slightly. More features will be coming further down the line to make retrieving queries even easier as we go.
Tags
One final update related to search, as if the above wasn't enough.
We have now added the ability to click any tag label to automatically filter your stash to that tag. Just click the label name in the UI and it will automatically update. You may also note that the URL of the page changes as well e.g. https://querystash.com/stash?tags=examples so you can easily bookmark or share if needed.
Need a refresher on creating queries, don't forget to checkout our intro guide
Explore some example SQL queries...
QUALIFY by ROW_NUMBER for cleaner queries
Using QUALIFY you can greatly simplify your query when dealing with RANK and ROW_NUMBER, and avoid having multiple sub queries.

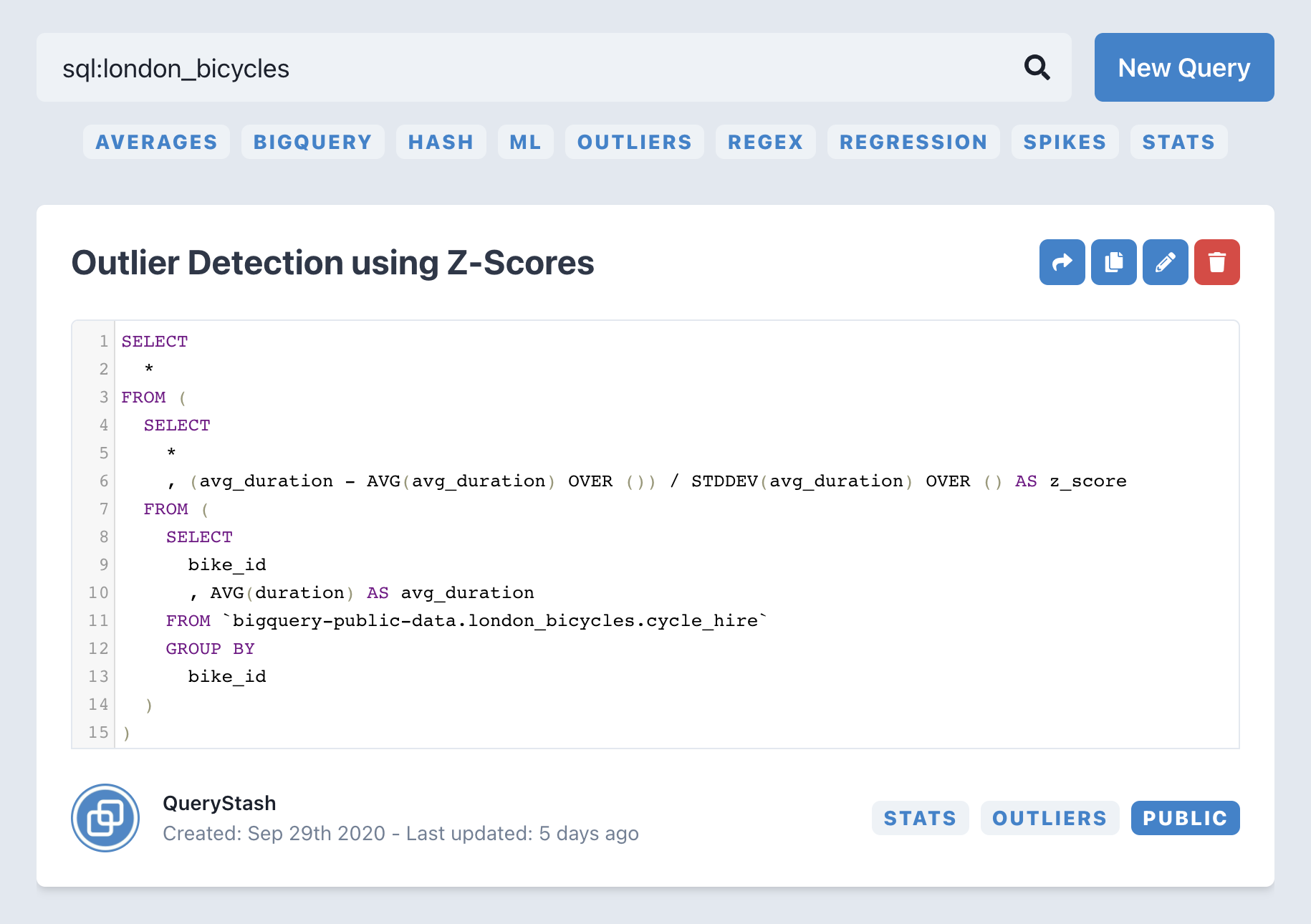
Spike Detection for Website Visits
To demonstrate one approach to spike detection, we are exploring website visitor data from the BigQuery Public Google Analytics sample data.

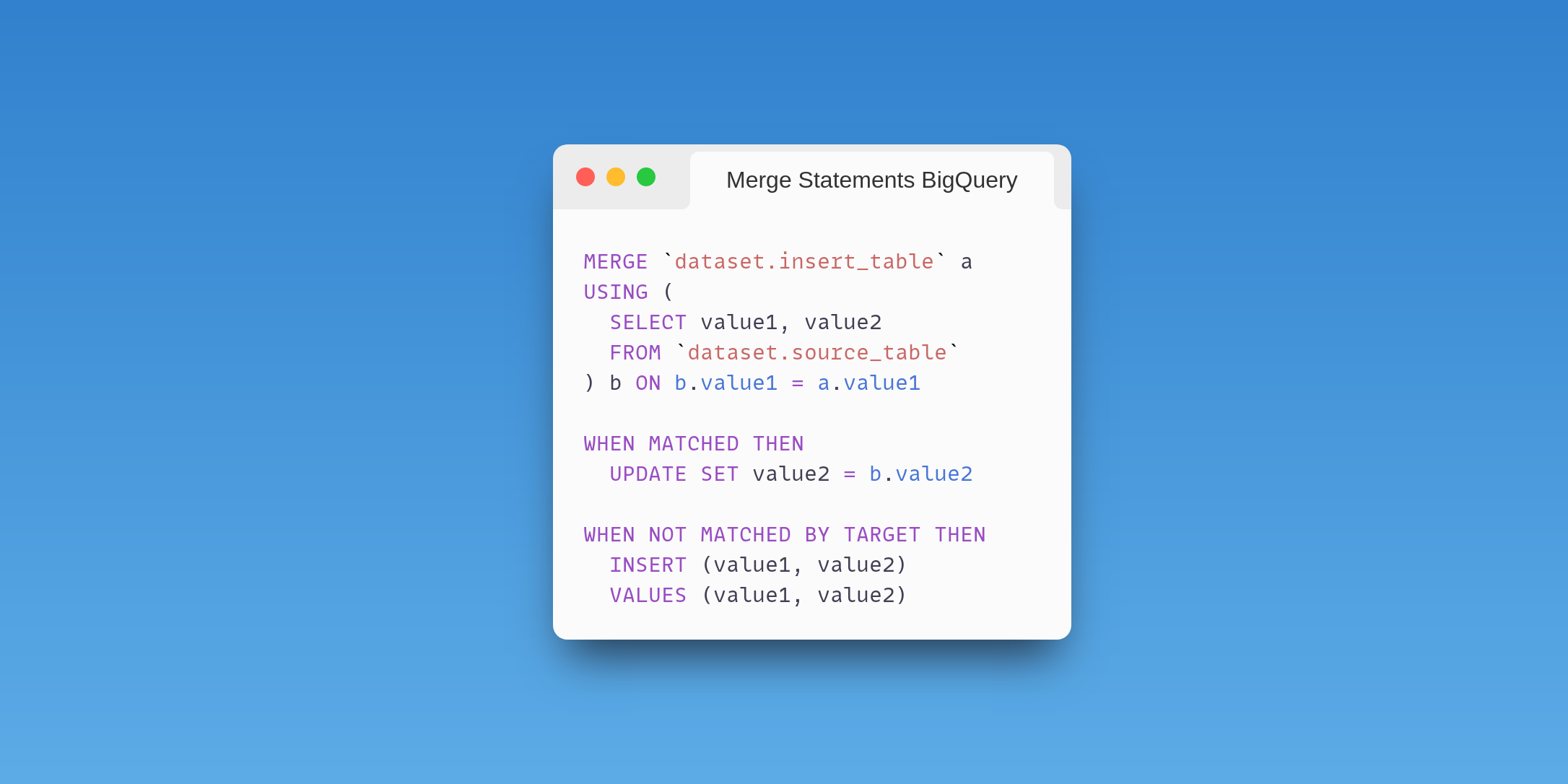
Merge Statements BigQuery
The combination of insert and update in a merge statement simplifies data processing where we don't know if a record already exists.
Create a Persistent Function on BigQuery
Persistent user-defined functions allow users to create custom functions that can be used across multiple queries and shared amongst users.

BigQuery Create ML Regression Model
Creating ML models has become even easier with BigQuery ML, create a new model in a few lines of SQL.

BigQuery Create Array of Structs
Working with flattened data might not always be the optimal way to work with data in BigQuery, use arrays to group data together into a single field.
