Welcome to QueryStash!

Blakey
—
Firstly, thank you for your time in reading this today and visiting my new project. Hopefully you have stumbled upon QueryStash with the goal of solving some of the very same problems I wanted to solve by building this product in the first place.
Let me start by introducing myself. My name is Chris the creator/founder of QueryStash, based out of the UK. With around 10+ years experience working in the "Data and Analytics" space for large global corporations, I'm now trying to solve some of the long overdue problems that many analytics teams face day to day. Helping to make both individuals and teams not only more productive, but also better at sharing, learning and collaborating.
Right now I am at the very beginning of this journey. A journey that has been laying its foundations for over a decade and I'm excited to hopefully have you along for the ride with us.
Ready to create your first query check out the intro guide
Thanks
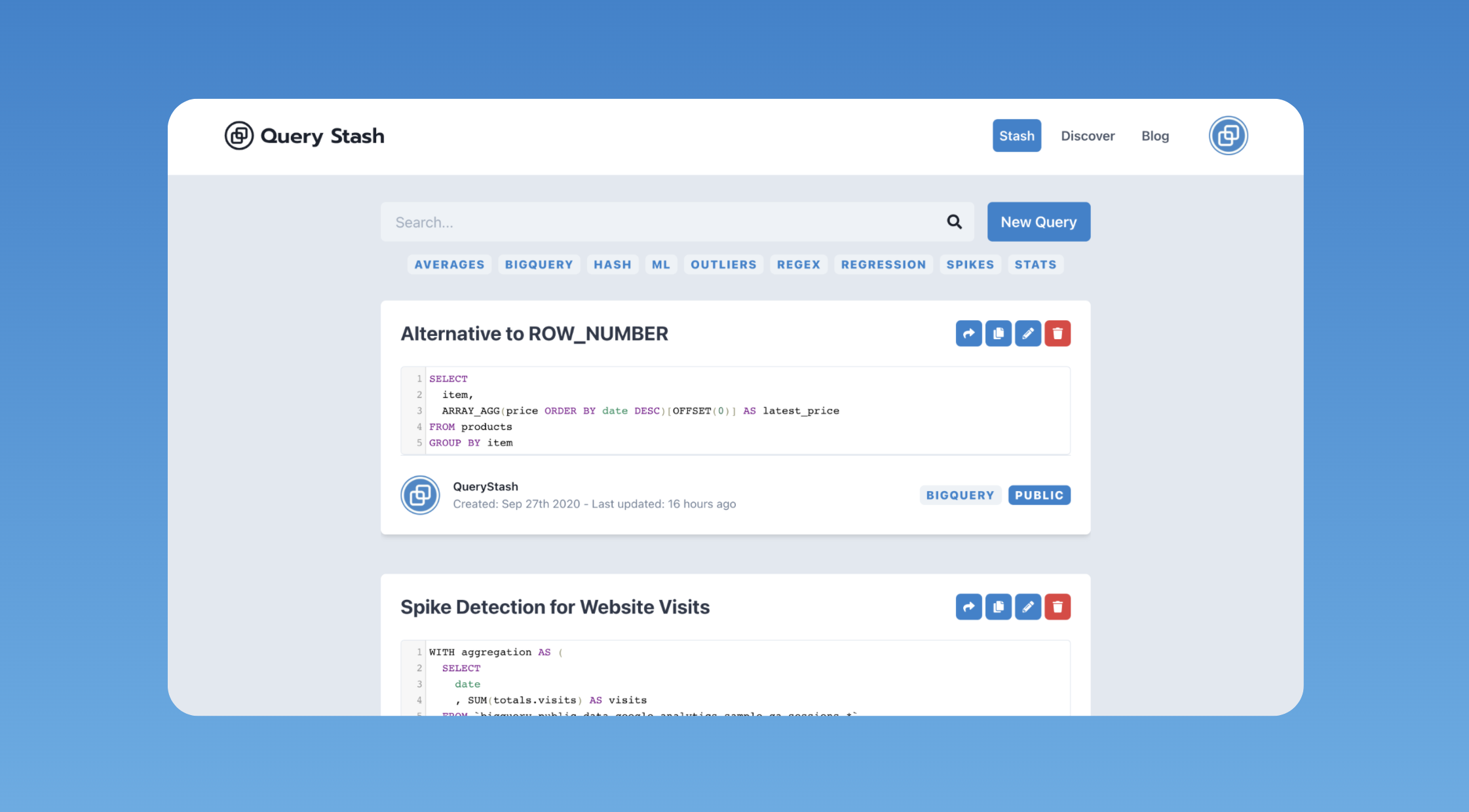
Explore some example SQL queries...
QUALIFY by ROW_NUMBER for cleaner queries
Using QUALIFY you can greatly simplify your query when dealing with RANK and ROW_NUMBER, and avoid having multiple sub queries.

Spike Detection for Website Visits
To demonstrate one approach to spike detection, we are exploring website visitor data from the BigQuery Public Google Analytics sample data.

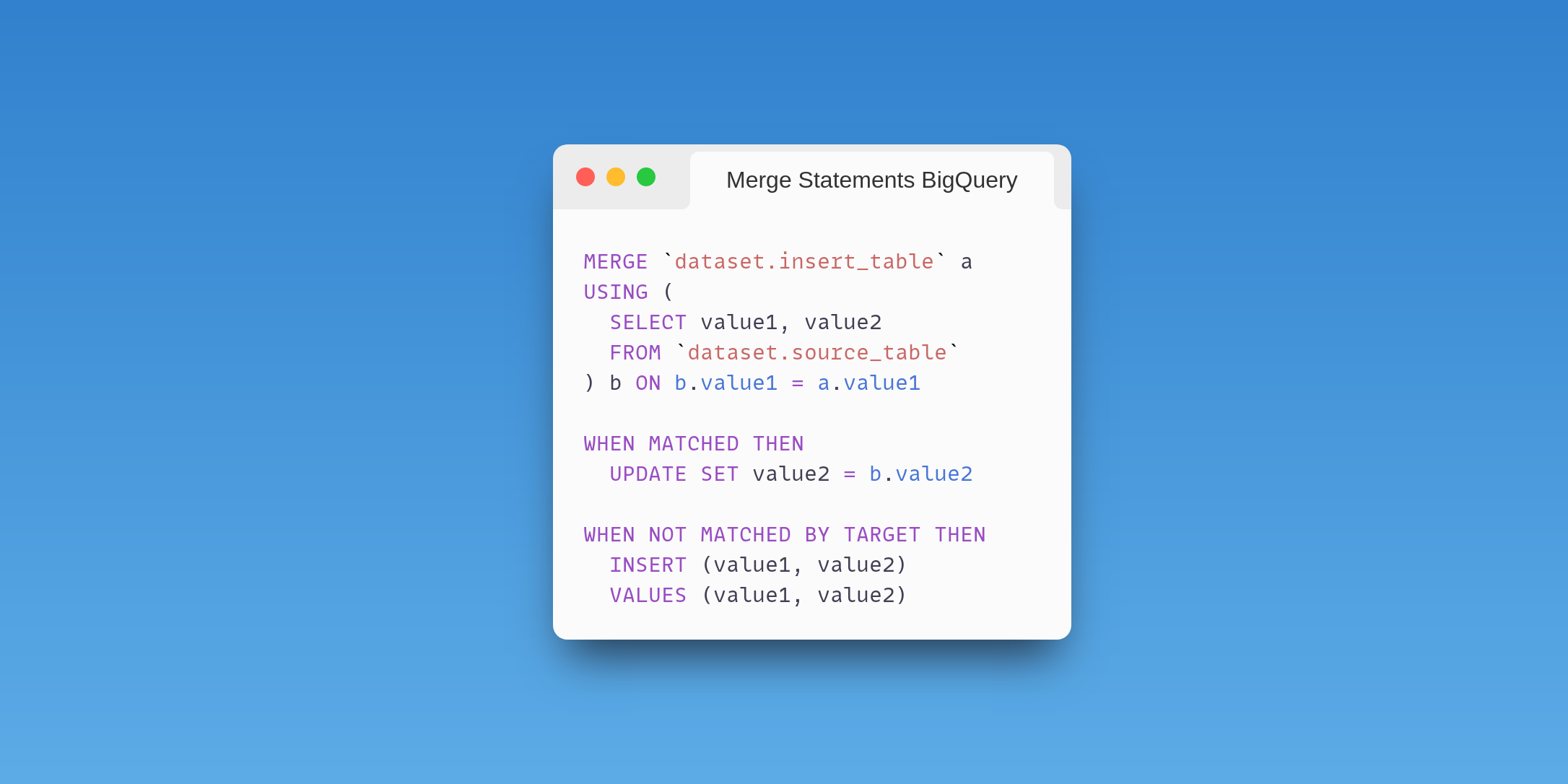
Merge Statements BigQuery
The combination of insert and update in a merge statement simplifies data processing where we don't know if a record already exists.
Create a Persistent Function on BigQuery
Persistent user-defined functions allow users to create custom functions that can be used across multiple queries and shared amongst users.

BigQuery Create ML Regression Model
Creating ML models has become even easier with BigQuery ML, create a new model in a few lines of SQL.

BigQuery Create Array of Structs
Working with flattened data might not always be the optimal way to work with data in BigQuery, use arrays to group data together into a single field.
