Getting Started with BigQuery SQL Persistent Functions

Blakey
—
What are Persistent Functions?
Persistent user-defined functions (UDFs) allow users to create custom functions that can be used across multiple queries and shared amongst users. A common use case might be for defining certain business logic rules or processing patterns that you might need to use across multiple different data processes. Using UDFs you can define the logic in one single place and re-use as needed like any other standard SQL function.
UDFs have been a feature of BigQuery for a very long time although a little clunky to use with having to include import statements in each query. This all changed in 2019 when Google released an update with the new persistent functions. Persistent functions now allowed BigQuery users to create UDFs within a projects dataset to enable them to be used by anyone with access, almost exactly the same as using any built in SQL function. All without having to import anything.
How do you create a Persistent Function?
Lets take a hypothetical use case, we have a query that processes referral URL's from one of our products. We need to process this data via BigQuery and would like to clean up the URL's into the actual company or product name.
For example given https://youtu.be/some_video_id we want to label as YouTube.
What does the function need to do?
For this use case we are really talking about a mapping, i.e. given some pre-defined rule set return a string value which labels the URL as required. The obvious solution for a problem like this in SQL might be a CASE statement.
If we were to write this in our SQL query it might look something like this:
SELECT
timestamp
, device_type
, target_url
, referral_url
, CASE
WHEN referral_url IS NULL THEN 'Direct'
WHEN REGEXP_CONTAINS(referral_url, '(?i)(twitter.com)') THEN 'Twitter'
WHEN REGEXP_CONTAINS(referral_url, '(?i)(youtube.com|youtu.be)') THEN 'YouTube'
ELSE 'Unknown'
END AS source
FROM website_traffic
Great so why do we need a function?
Now there is nothing at all wrong with doing this and using a CASE statement in the query itself is exactly what CASE statements are designed for.
The problem becomes when either:
- The list of different mapping statements we have becomes very long.
- We want to re-use the same mapping for a different data process.
In these cases it either leads to very long query statements where there might be risk of error or duplications of similar business logic that then needs maintaining in multiple different places and risks becoming out of sync with each other.
So how do we turn this into a function?
So first of all we need to define that we want to CREATE a new function. Within this statement we can define where we want to store the function, i.e. which project and dataset. What we want to call the function and what inputs the function can except when called.
CREATE OR REPLACE FUNCTION `project-name.dataset_name.function_name`(input_name STRING) AS (...);
Note we also use the OR REPLACE this is useful for once you create your function and updates will overwrite the previous version.
Tip: I generally create a dataset specifically to hold functions so that I can easily find them when needed. Using a dataset name like
functionsorfuncorudfcan be useful to organize them.
Now we need to define what the function actually does, so in our case we can copy the CASE statement we used previously into our new UDF definition. The full example looks like so:
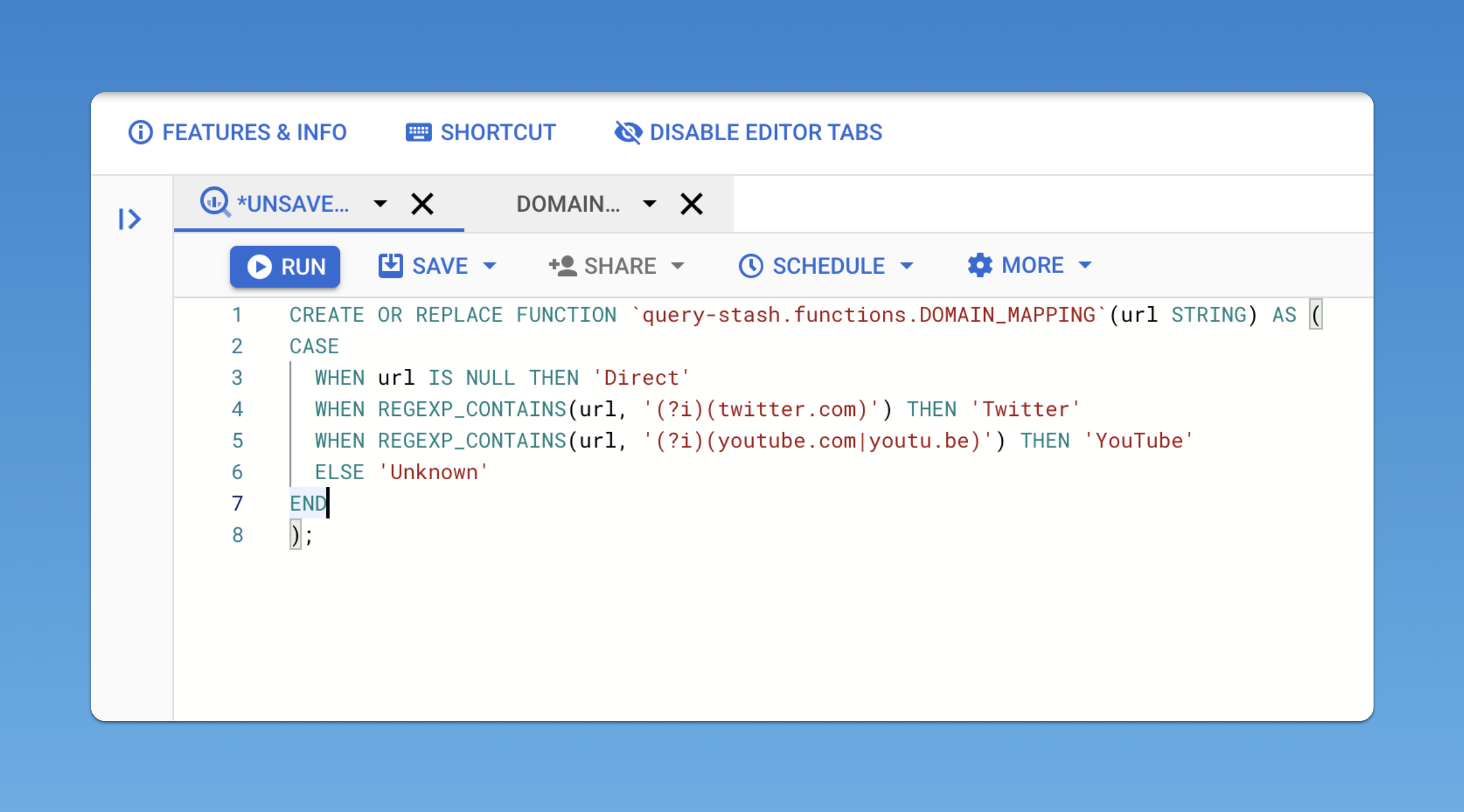
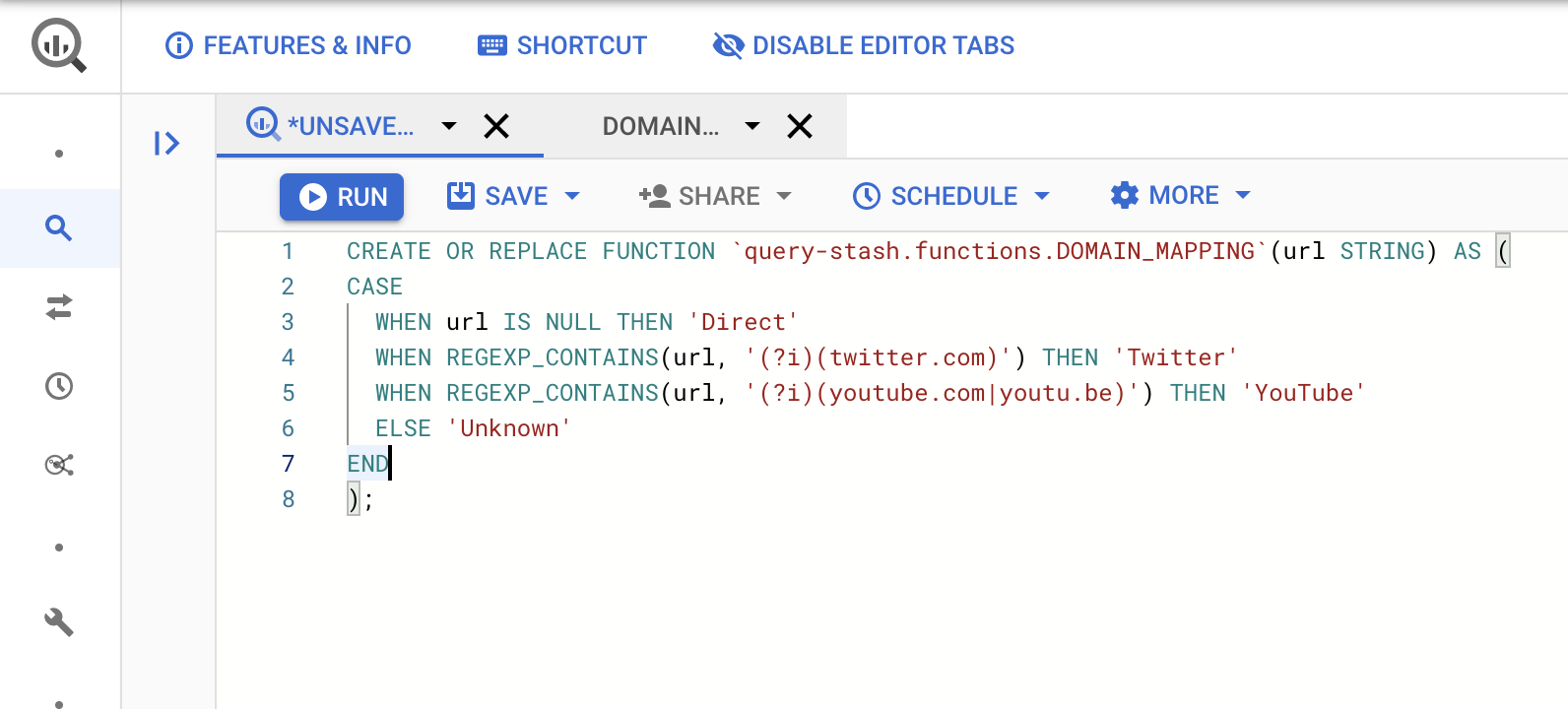
CREATE OR REPLACE FUNCTION `query-stash.functions.DOMAIN_MAPPING`(url STRING) AS (
CASE
WHEN url IS NULL THEN 'Direct'
WHEN REGEXP_CONTAINS(url, '(?i)(twitter.com)') THEN 'Twitter'
WHEN REGEXP_CONTAINS(url, '(?i)(youtube.com|youtu.be)') THEN 'YouTube'
ELSE 'Unknown'
END
);
Now lets go ahead and run the query above in your BigQuery UI, all being well the query will execute successfully. If you look at your dataset explorer you should now see a new items added in the Routines dropdown.

How do we now use the Persistent Function?
Once you have successfully create your new function, using it is as simple as using SUM(). We can now invoke a function simple by referring to its location in our query in this example we can call `query-stash.functions.DOMAIN_MAPPING`(url)
Lets update our original query to now use the persistent function instead:
SELECT
timestamp
, device_type
, target_url
, referral_url
, `query-stash.functions.DOMAIN_MAPPING`(referral_url) AS source
FROM website_traffic
As you can see this is a much cleaner version of the original query and now means that we can manage and edit the business logic in one single place and be confident that any other queries using this function will all be using the same rules.
Finally
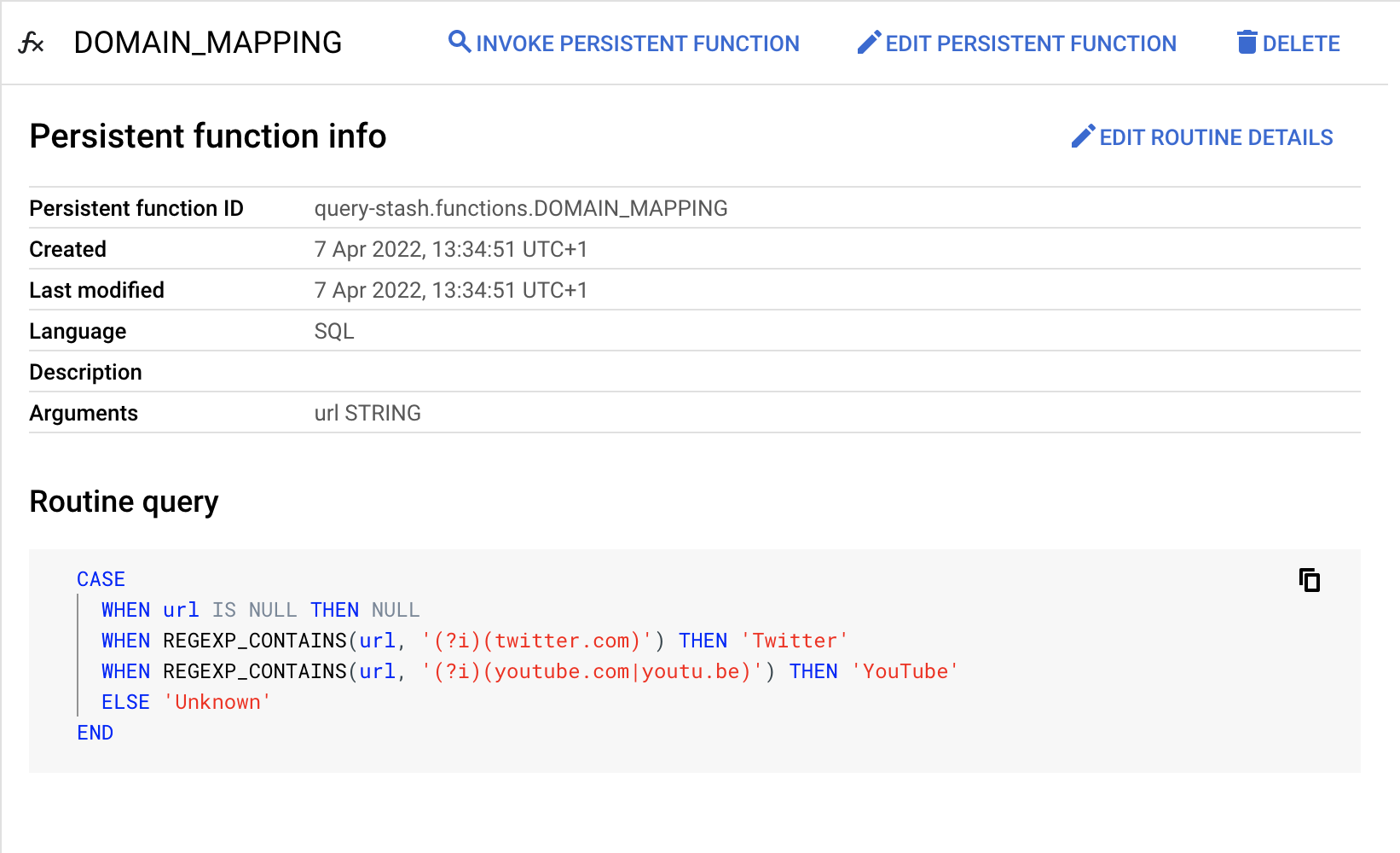
If you open the persistent function in the BigQuery UI, it provides details about the function in terms of its ID, which arguments it accepts and a code snippet so you can see what it does.
There are also useful buttons to invoke, edit or delete the function. The edit function button will auto populate the query window with the CREATE OR REPLACE function from above.
Explore some example SQL queries...
QUALIFY by ROW_NUMBER for cleaner queries
Using QUALIFY you can greatly simplify your query when dealing with RANK and ROW_NUMBER, and avoid having multiple sub queries.

Spike Detection for Website Visits
To demonstrate one approach to spike detection, we are exploring website visitor data from the BigQuery Public Google Analytics sample data.

Merge Statements BigQuery
The combination of insert and update in a merge statement simplifies data processing where we don't know if a record already exists.
Create a Persistent Function on BigQuery
Persistent user-defined functions allow users to create custom functions that can be used across multiple queries and shared amongst users.

BigQuery Create ML Regression Model
Creating ML models has become even easier with BigQuery ML, create a new model in a few lines of SQL.

BigQuery Create Array of Structs
Working with flattened data might not always be the optimal way to work with data in BigQuery, use arrays to group data together into a single field.
